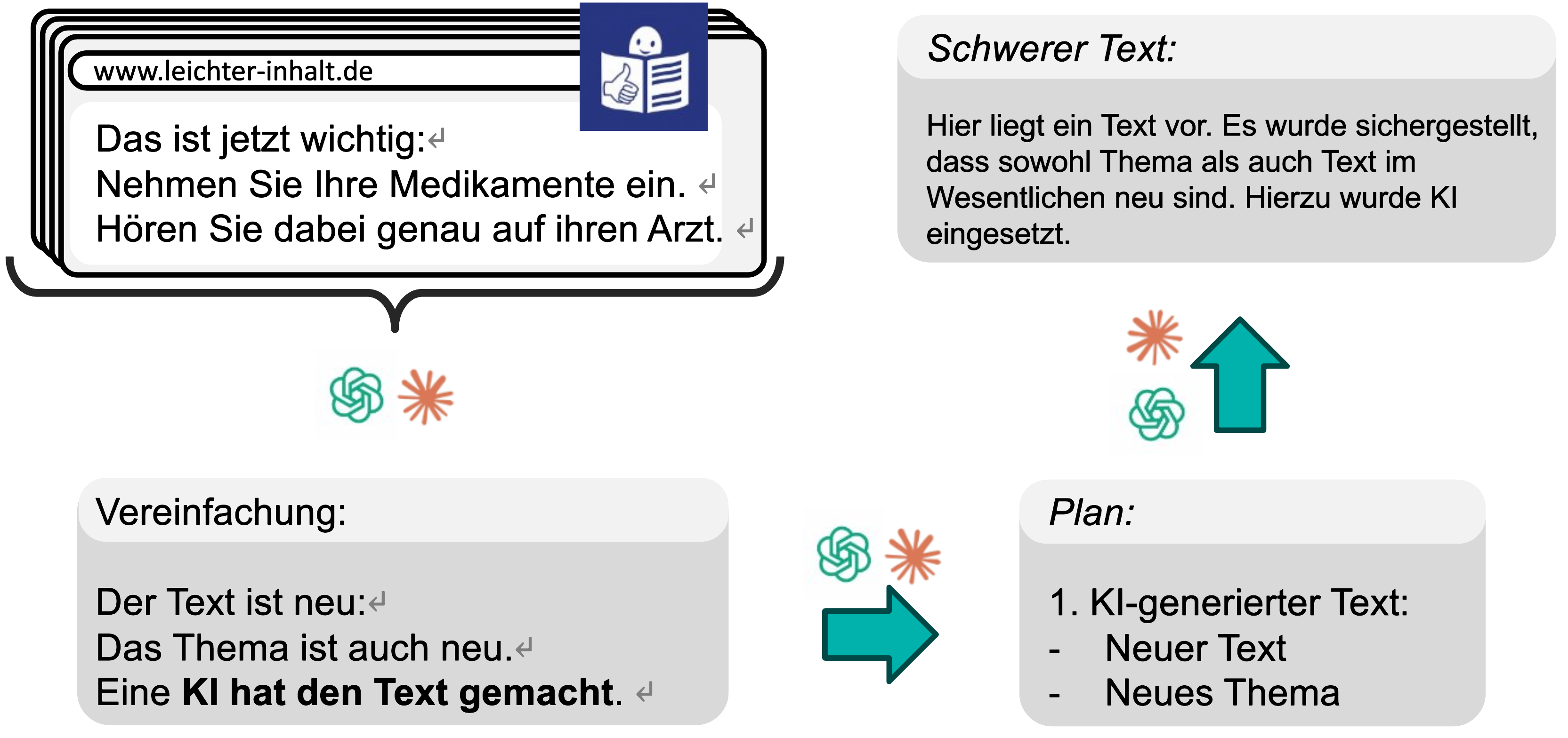
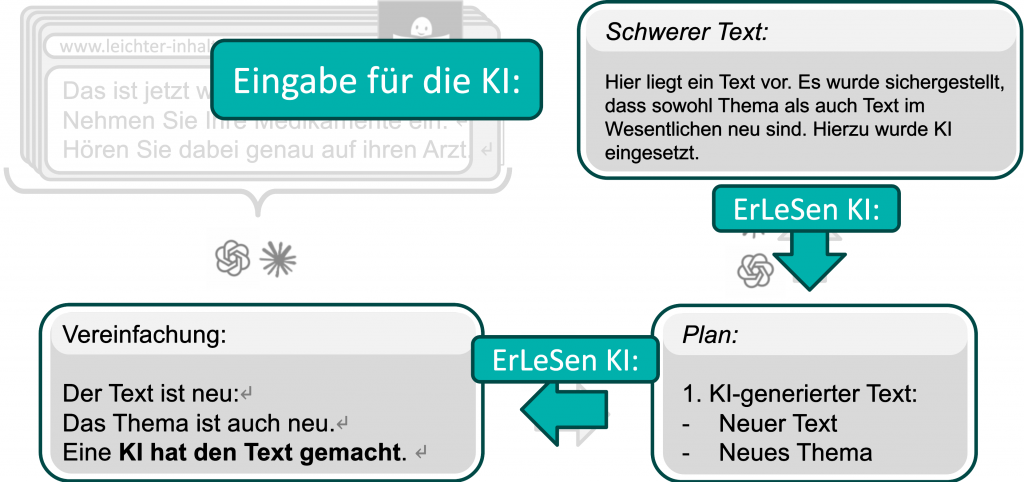
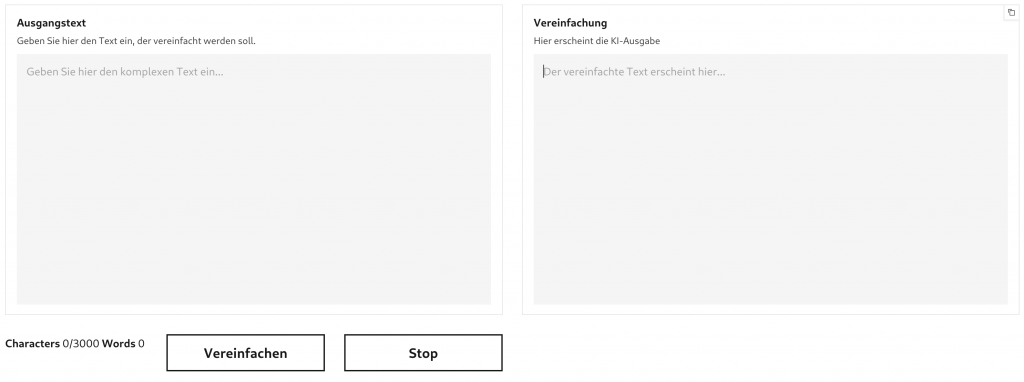
Aufgrund des enormen und anhaltenden technischen Fortschritts in dieser Domäne wurde die Notwendigkeit für eine objektive, Metrik-basierte Evaluationssystematik erkannt. Diese ermöglicht es, die Qualität, der heute verfügbaren und der zukünftig entwickelten KI-Modelle automatisiert zu bewerten. Zudem können die aktuell noch unzureichenden aber stark wachsenden Potentiale kleinerer Sprachmodelle überwacht werden. Gerade in der aktuellen Diskussion um neue Entwicklungen, wie z.B. DeepSeek, zeigt sich, dass eine schnelle und verlässliche Evaluierung neuer Basistechnologien erforderlich ist, um die heutige Lösung an den jeweils optimalen, aktuellen Stand anzupassen.