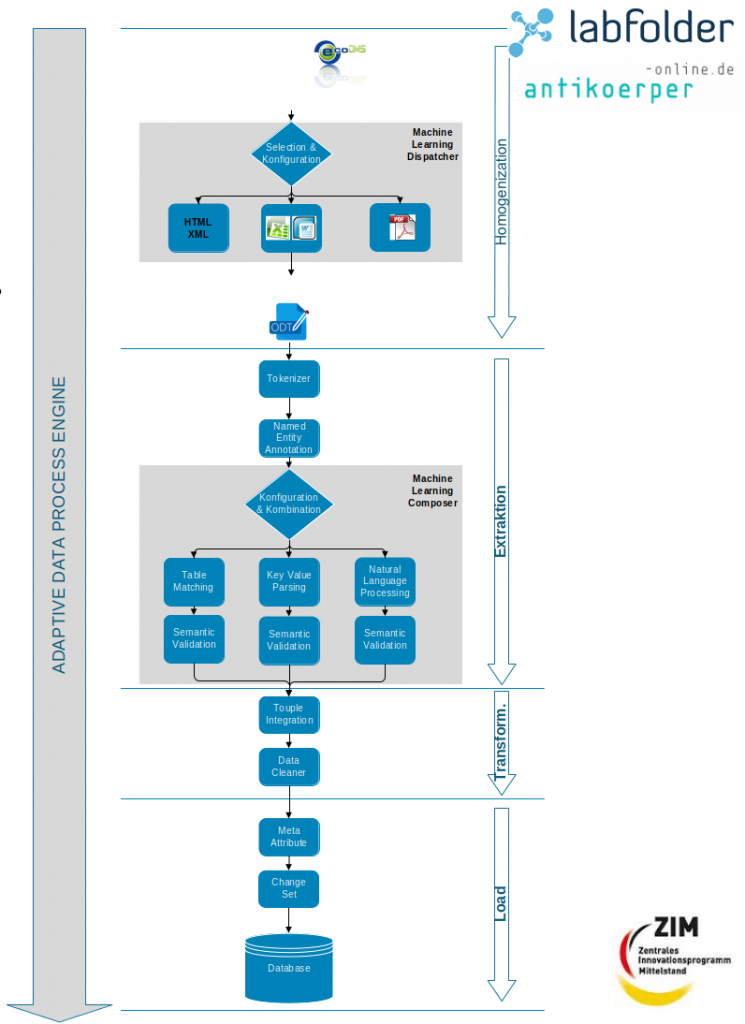
Die Dunkelverarbeitung von Daten wird im Allgemeinen durch einen Extract, Transform, Load (ETL) Prozess abgebildet. Dabei werden zunächst Informationen aus Eingangsdokumenten extrahiert und anschließend in ein Arbeitsformat transformiert. Danach werden die Daten mit Informationen angereichert und aufbereitet. Abschließend werden die Daten in einer Datenbank für anschließende Geschäftsprozesse zur Verfügung gestellt.
Damit ein ETL-Prozess auf unbekannten, unstrukturierten Daten durchgeführt werden kann, müssen die Daten aus dem Eingangsdokument in ein gemeinsames Datenformat überführt werden.
Im Rahmen des Projekts wurden Verfahren und Konzepte entwickelt, die für eine möglichst breite Auswahl von Eingabedokumenten eine robuste, korrekte und effiziente Überführung der enthaltenen relevanten Informationen in den produktiven Datenbestand ermöglicht.
Die hoch performante Datenaufarbeitung transformiert die identifizierten Datenformate dabei in eine aggregierbare Datenstruktur. Hierbei wurden verschiedene Technologien aus den Bereichen Semantik-Web, Natural Language Processing (NLP) und Machine Learning auf ihre Praxistauglichkeit überprüft und ggf. in moderne Microservice-Architekturen überführt.
Die Projektergebnisse zeigen, dass die Verbindung von NLP-Verfahren mit klassischem ETL einen erheblichen Mehrwert zur Datenaufbereitung und -integration bringen kann.