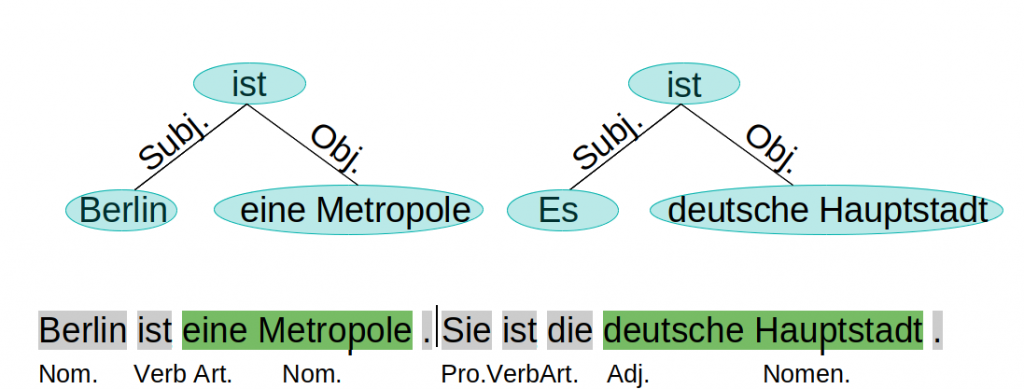
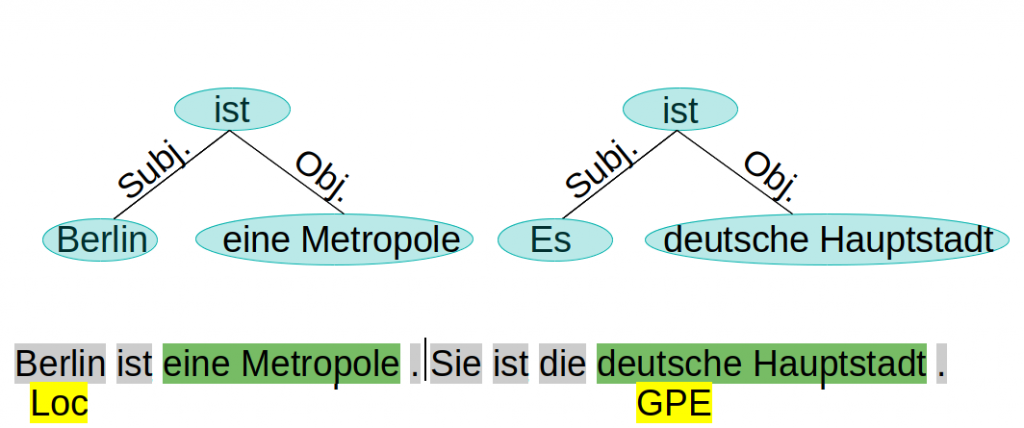
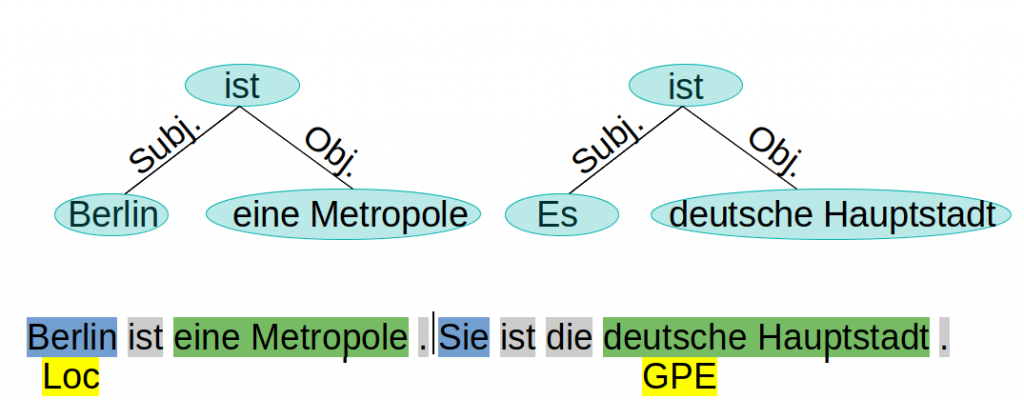
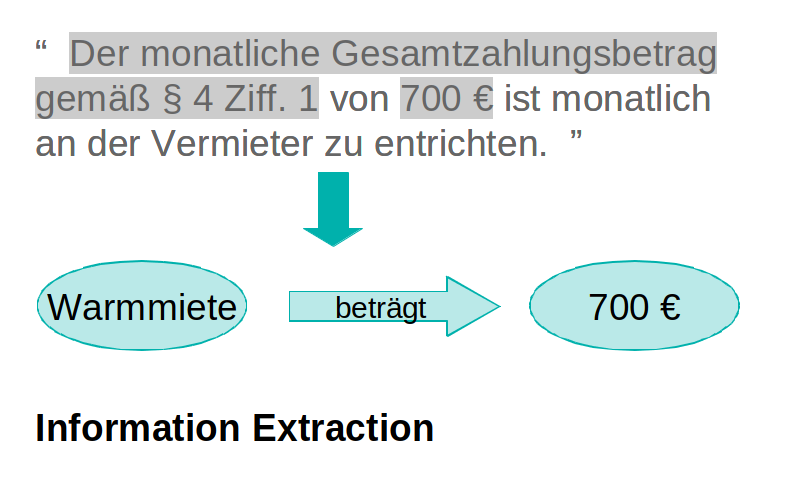
Die Vielseitigkeit natürlicher Sprache mach die autromatisierte Verarbeitung zu einer großen Herausforderung. Im Umfeld des Natural Language Prozessing (NLP) hat sich ein variabler Prozess mit verschiedenen Stufen etabliert. Die einzelnen Stufen lassen sich als Klassifikationsprobleme beschreiben.
Ein Ziel dieses Projektes ist es mit State-of-the-Art Ansätze auf deutsche rechtliche Texte anzuwenden.